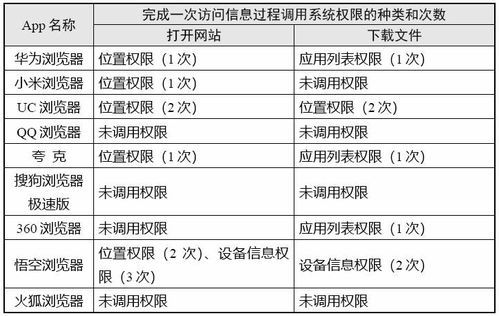
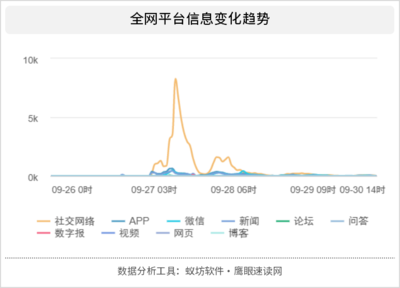
防范大模型幻觉 新闻信息采集中的信息安全新挑战与应对策略

随着人工智能技术的飞速发展,大模型(如GPT-4、文心一言等)在新闻信息采集、内容生成与分析中扮演着越来越重要的角色。大模型固有的“幻觉”(Hallucination)问题——即生成看似合理但实际错误或虚构的信息——正成为信息安全领域的新隐患。在新闻信息采集中,这一问题若未被有效识别与控制,可能导致虚假信息传播、舆论误导甚至社会秩序紊乱,亟需引起高度重视并采取系统性防范措施。
一、大模型幻觉在新闻采集中的具体风险
- 虚假新闻生成:大模型可能基于不完整或噪声数据“脑补”出细节,生成包含错误时间、地点、人物或事件的新闻内容,若被直接采用,将加剧虚假信息泛滥。
- 信源扭曲与误导:在自动抓取和摘要生成过程中,模型可能曲解原始信源,遗漏关键语境或添加主观臆断,导致新闻失真,影响公众判断。
- 深度伪造内容辅助:大模型可生成逼真文本描述,与图像、视频生成技术结合后,可能助长深度伪造新闻的规模化生产,挑战信息真实性防线。
- 意识形态与偏见放大:若训练数据存在偏差,模型幻觉可能无意识强化特定立场或刻板印象,影响新闻客观性,甚至被恶意利用进行宣传渗透。
二、核心成因:技术局限与人为漏洞
- 数据依赖性:大模型依赖于训练数据的质量与覆盖度,若数据包含错误或过时信息,模型可能延续并放大这些缺陷。
- 概率生成机制:模型基于统计概率生成文本,追求流畅性而非真实性,在缺乏明确事实约束时易“自由发挥”。
- 提示词诱导:不当的查询指令可能触发模型的创造性幻觉,尤其在开放域新闻采集中风险更高。
- 人为监督缺失:全自动化流水线若缺乏人工审核与事实核查环节,幻觉信息极易渗透至发布终端。
三、多维防范策略:技术、制度与协同治理
1. 技术层面加固
- 可信度增强技术:在模型中嵌入事实核查模块,实时比对权威数据库(如政府公报、学术期刊),对生成内容进行可信度评分与预警。
- 可解释性提升:开发可视化工具追踪信息生成路径,标注数据来源与推断逻辑,便于人工复核。
- 对抗性训练:引入对抗样本训练模型识别并抵制幻觉倾向,提高对模糊查询的稳健性。
2. 流程制度优化
- 人机协同审核:建立“AI采集+人工校验”双轨制,关键新闻需经多信源交叉验证后方可发布。
- 透明化标注:对AI参与生成的新闻明确标注技术使用范围与人工干预程度,保障公众知情权。
- 动态黑名单机制:针对反复出现幻觉的领域或信源建立风险清单,限制模型在这些场景下的自主发挥。
3. 行业生态共建
- 标准制定:新闻行业与技术机构合作制定AI内容安全标准,规范训练数据质量、输出审核流程。
- 共享数据库:建设行业级事实核查共享平台,汇总已验证的虚假新闻案例与纠正信息,助力模型迭代。
- 伦理培训:对新闻从业者开展AI伦理与安全培训,提升技术风险识别与应急处置能力。
四、未来展望:平衡创新与安全
防范大模型幻觉非一朝一夕之功,需持续投入研发资源,探索更精准的事实对齐算法。应避免因过度防范扼杀技术潜力——在确保信息安全的前提下,充分发挥大模型在信息筛选、趋势分析中的效率优势。立法机构也需与时俱进,明确AI生成新闻的责任归属,构建权责清晰的法律框架。
大模型幻觉是新闻信息采集中不容忽视的“暗礁”,唯有通过技术创新、流程规范与跨领域协作形成合力,才能驾驭技术浪潮,守住信息安全的生命线,推动新闻行业在智能时代行稳致远。
如若转载,请注明出处:http://www.fhtxsqb.com/product/91.html
更新时间:2026-06-18 14:23:38